Однопроцессорные архитектуры ЭВМ
Исторически первыми появились однопроцессорные архитектуры. Классическим примером однопроцессорной архитектуры является архитектура фон Неймана со строго последовательным выполнением команд: процессор по очереди выбирает команды программы и также по очереди обрабатывает данные. По мере развития вычислительной техники архитектура фон Неймана обогатилась сначала конвейером команд, а затем многофункциональной обработкой и по классификации М.Флина получила обобщенное название SISD (Single Instruction Single Data — один поток команд, один поток данных). Основная масса современных ЭВМ функционирует в соответствии с принципом фон Неймана и имеет архитектуру класса SISD.
Данная архитектура породила CISC, MSC и архитектуру с суперскалярной обработкой (рис. 1.1).
Компьютеры с CISC (Complex Instruction Set Computer) архитектурой имеют комплексную (полную) систему команд, под управлением которой выполняются всевозможные операции типа «память-память», «память-регистр», «регистр — память», «регистр — регистр».
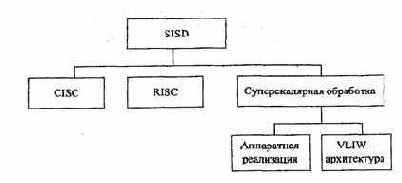
Рис. 1.1. Классификация архитектуры SISD
Данная архитектура характеризуется:
- большим числом команд (более 200);
- переменной длиной команд (от 1 до 11 байт);
- значительным числом способов адресации и форматов команд;
- сложностью команд и многотактностыо их выполнения;
- наличием микропрограммного управления, что снижает быстродействие и усложняет процессор.
Обмен с памятью в процессе выполнения команды делает практически невозможной глубокую конвейеризацию арифметики, т.е. ограничивается тактовая частота процессора, а значит, и его производительность.
Большинство современных компьютеров типа IBM PC относятся к CISC архитектуре, например, компьютеры с микропроцессорами (МП) 8080, 80486, 80586 (товарная марка Pentium).
Компьютеры с RISC (Reduced Instruction Set Computer) архитектурой содержат набор простых, часто употребляемых в программах команд. Основными являются операции типа «регистр — регистр».
Данная архитектура характеризуется:
- сокращенным числом команд;
- тем, что большинство команд выполняется за один машинный такт;
- постоянной длиной команд;
- небольшим количеством способов адресации и форматов команд;
- тем, что для простых команд нет необходимости в использовании микропрограммного управления;
-
большим числом регистров внутренней памяти процессора.
Компьютеры с RISC-архитектурой «обязаны» иметь преимущество в производительности по сравнению с CISC компьютерами, за которое приходится расплачиваться наличием в программах дополнительных команд обмена регистров процессора с оперативной памятью.
В настоящее время практически все ведущие производители компьютеров прилагают большие усилия для производства RISC-процессоров (см. табл. 1.1).
Таблица 1.1
Название фирм и разработанных ими RISC-процессоров
|
Фирма |
RISC-процессор |
|
Sun Microsystems |
Ultra SPARC II |
|
Ultra SPARC III |
|
|
DEC |
Alpha 21164 |
|
HP |
PA-7150, PA-8000 |
|
SGI |
MIPS R-10000 |
|
IBM |
PPC-601, PPC-604 |
|
Motorola |
88000 |
Смысл этого термина заключается в том, что в аппаратуру процессора закладываются средства, позволяющие одновременно выполнять две или более скалярные операции, т.е. команды обработки пары чисел. Суперскалярная архитектура базируется на многофункциональном параллелизме и позволяет увеличить производительность компьютера пропорционально числу одновременно выполняемых операций. Способы реализации суперскалярной обработки могут быть разными. Первый способ применяется как в CISC, так и в RISC - процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша инструкций) несвязанных команд и параллельном запуске их на исполнение.
В табл. 1.2 для различных типов процессоров приведено максимальное и среднее число команд, выполняемых в одном машинном цикле.
Этот метод хорош тем, что он «прозрачен» для программиста, составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства.
Таблица 1.2
Максимальное и среднее число команд, выполняемых в одном машинном цикле
|
Процессор |
Тактовая частота, Мгц |
Число транзисторов, млн. |
Максимальное число команд на цикл |
Среднее число команд на цикл |
|
Digital Alpha |
500 |
9,3 |
4 |
1,0 |
|
Power PC 620 |
200 |
6,9 |
4 |
1,8 |
|
Power PC 604с |
225 |
5,1 |
4 |
1,5 |
|
Ultra SPARC |
250 |
3,8 |
4 |
1,36 |
|
HP PA-8000 |
180 |
3,9 |
4 |
2,4 |
|
HPPA-7300LC |
160 |
9,2 |
2 |
1,35 |
|
Mips R10000 |
200 |
5,9 |
4 |
1,78 |
|
Mips R 5000 |
180 |
3,6 |
2 |
0,89 |
|
i486 |
25 |
1,2 |
- |
0,45 |
|
Pentium Pro |
200 |
5,5 |
3 |
1,76 |
реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует несвязанные операции в пакеты, содержимое которых строго соответствует структуре процессора.
Например, если процессор содержит функционально независимые устройства (сложения, умножения, сдвига и деления), то максимум, что компилятор может «уложить» в один пакет - это четыре разнотипные операции:
(сложение, умножение, сдвиг и деление). Сформированные пакеты операций преобразуются компилятором в командные слова, которые по сравнению с обычными инструкциями выглядят очень большими.
Отсюда и название этих суперкоманд и соответствующей им архитектуры - VLIW (Very Large Instruction Word - очень широкое командное слово). По идее, затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, с которого снята вся «интеллектуальная» работа по поиску параллелизма несвязанных операций. Однако практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции.
Архитектуры класса SISD охватывают те уровни программного параллелизма, которые связаны с одинарным потоком данных. Они реализуются многофункциональной обработкой и конвейером команд.
Параллелизм циклов и итераций тесно связан с понятием множественности потоков данных и реализуется векторной обработкой. В классификации компьютерных архитектур М. Флина выделена специальная группа однопроцессорных систем с параллельной обработкой потоков данных - SIMD (Single Instruction Multiple Date, один поток команд - множество потоков данных).
Возможны два способа построения компьютеров этого класса. Это матричная структура и векторно-конвейерная обработка. Суть матричной структуры заключается в том, что имеется множество процессорных элементов, исполняющих одну и ту же команду над различными элементами вектора, объединенных коммутатором. Основная проблема заключается в программировании обмена данными между процессорными элементами через коммутатор.
В отличие от матричной, векторно-конвейерная структура компьютера содержит конвейер операций, на котором обрабатываются параллельно элементы векторов и полученные результаты последовательно записываются в единую память. При этом отпадает необходимость в коммутаторе процессорных элементов, служащем камнем преткновения в матричных компьютерах.
Примером векторных супер-ЭВМ с матричной структурой является знаменитая в свое время система ILLIAC-IV.
Векторно-конвейерную структуру имеют однопроцессорные супер-ЭВМ серии VP фирмы Fujitsu; серии S компании Hitachi; C90, М90, Т90 фирмы Cray Research; Cray-3, Cray-4 фирмы Cray Computer и т.д.
Общим для всех векторных суперкомпьютеров является наличие в системе команд векторных операций, допускающих работу с векторами определенной длины, допустим, 64 элемента по 8 байт. В таких компьютерах операции с векторами обычно выполняются над векторными регистрами.
Еще одним примером SIMD-архитектуры является технология ММХ, которая существенно улучшила архитектуру микропроцессоров фирмы Intel. Она разработана для ускорения выполнения мультимедийных и коммуникационных программ. В ММХ используются 4 новых типа данных и 57 новых инструкций. Команды ММХ выполняют одну и ту же функцию с различными частями данных, например, 8 байт графических данных передаются в процессор как одно упакованное 64-х разрядное число и обрабатываются одной командой. ММХ - команды используют восемь 64-разрядных регистров, «физически» размещенных в мантиссах регистров с плавающей запятой, и используются в том же режиме процессора, что и команды с плавающей запятой.
Все программное обеспечение, созданное для ранее выпущенных процессоров, без всяких изменений может выполняться на процессорах с технологией ММХ.
